LM-Nav Robotic Navigation
Now robots move where exactly you want them to

Introduction
Ever wondered if you could give instructions in general English and a robot could do it as u intended? well it seems far from fiction with this new research which made a robot navigate based on instructions from humans, this could prove very beneficial say at a restaurant a robot could be given instructions to give this meal to the man with white hat and orange shirt and robot could deliver it

All this didn’t take some new technology for it to happen but smart use of individual models that have separate effects and combine them to produce a new use case this was made out of three transformer models, them being: a large language model such as gpt-3, a vision, and language model, a Visual Navigation Model, basically one model to understand the language one model to ground that language in an image and another model to actuate it.
All of these models are readily available to the public and a demonstration of this on google Collab is also available for the public to try their hand at it u can find the Collab link here
LM-Nav
The general problem statement they took on to solve is Given a high-level textual instruction for navigating a real-world environment, to get a robot to follow it solely from the egocentric vision(a first-person view of the environment around via images
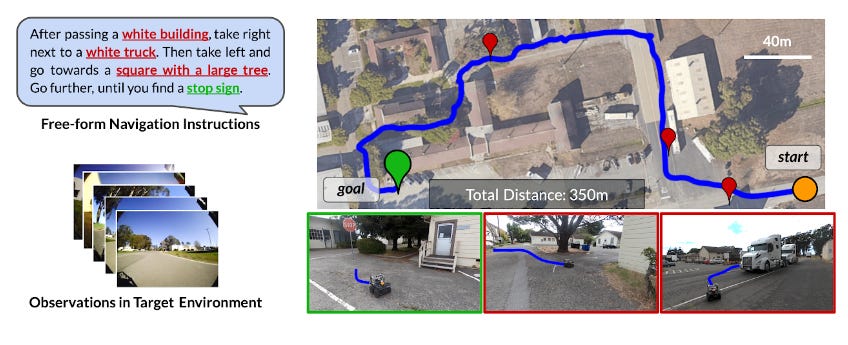
they used pre-trained models of language and images to provide a textual interface to visual navigation models, the language model takes the complex natural language instruction given by a person and tries to extract keywords that work as landmarks to it and make a set of instructions its should follow, next the vision and language model aim is given an egocentric image determine which are what objects are present in the image and search for the objects that were asked in the instructions after this once we found a landmark in the image our robot needs to reach that place for which we use the navigation model, using all of this a plan is generated which then is executed by the robot sequentially.

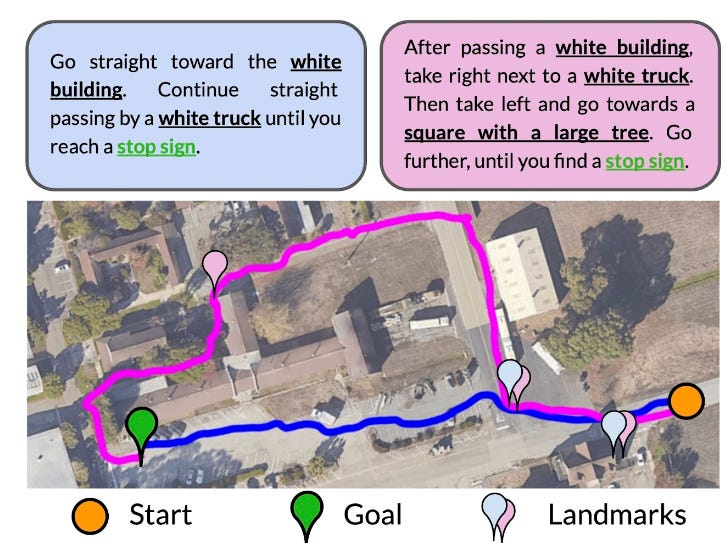
Language is complex and there may be multiple paths to the goal that satisfy the given instructions. In such cases, an instruction-following system must be able to choose paths in the environment that we want exactly using fine-grained modifications to the instruction. They show an experiment where LM-Nav is tasked with two slightly different instructions for the same goal. when instructions were a little more fine-grained it took the intended path rather than the correct but not intended path
References
https://sites.google.com/view/lmnav
https://colab.research.google.com/github/blazejosinski/lm_nav/blob/main/colab_experiment.ipynb#scrollTo=119d7a8c
https://arxiv.org/abs/2207.04429